
Automation is only as powerful as its reliability. In testing, infrastructure, or process automation, hours of engineering can vanish if failure creeps in unnoticed. Early detection isn’t just about saving headaches—it’s about saving your pipeline, protecting your release schedule, and keeping your stakeholders confident. In this guide, you’ll learn how to detect automation failure early, spot the silent signs of trouble, and build resilient systems that thrive even when things go wrong. If you’ve wondered how the best engineering teams stay ahead of automation breakdowns—or if previous failures have taught you costly lessons—this is for you.
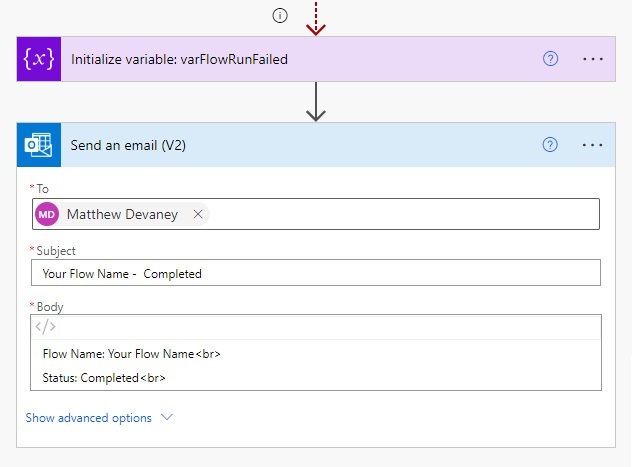
What is Early Detection of Automation Failure?
Early detection of automation failure refers to identifying issues, disruptions, or breakdowns in your automated pipelines as soon as—or even before—they occur. This is about more than just finding bugs: it’s about proactively surfacing hidden errors and system bottlenecks before they degrade your workflow, damage data, or reach customers.
Automation systems—from CI/CD pipelines to RPA bots—can fail due to flaky tests, environment drift, integration errors, script obsolescence, data inconsistencies, or external dependency shifts. Often, these failures manifest silently first: subtle increases in run time, overlooked errors in logs, or irregular resource consumption. To detect automation failure early, you need strategies and tools that provide fast feedback and actionable insight before issues spiral.
Why Detecting Automation Failures Early Matters
Early detection brings a host of business and technical benefits. Here’s what’s at stake when it comes to identifying automation breakdowns early in your process:
- Minimize Downtime: Quicker response prevents cascading outages.
- Reduce Mean Time to Recovery (MTTR): Know what broke, where, and why—for faster fixes.
- Increase Test and Deployment Confidence: Catch flaky or unstable tests before they block progress.
- Save Costs: Prevent expensive production failures and avoid rework.
- Protect Data Integrity: Stop corrupt or incomplete data processing before it leaves your QA/test/production pipeline.
- Continuous Feedback: Teams learn fast, adapt, and build higher-quality automation next sprint.
Not only will you maintain your release velocity, but your organization’s credibility and customer trust remain intact.

Use Cases & Real-World Examples of Automation Failure
Let’s ground this guide with practical examples where automation failure, if left unchecked, can create significant downstream impacts and how early detection can flip the narrative:
- CI/CD Pipeline Failures: A regression suite hangs indefinitely, halting all deploys for hours before a timeout reveals a missing dependency.
- Data Pipeline Automation: Silent schema changes push corrupt records downstream. Only after customer complaints do failures surface.
- QA/Test Automation: “Green” tests that actually pass because assert conditions are wrong, not because the software is bug-free.
- Security Automation: Automated alerts fail to trigger as attackers exfiltrate sensitive data undetected.
- Infrastructure Management: Bots spin up resources that fail health checks, silently wasting budget.
Every scenario highlights a truth: It’s always cheaper and safer to catch automation trouble early, not late.
How to Detect Automation Failure Early: A Step-by-Step Approach
Step 1: Establish Baselines and Observable Metrics
Start by defining what “normal” looks like for your automation. Use metrics such as pipeline execution time, pass/fail counts, resource usage, and error rates.
- Track historical trends in test runs
- Record every error, warning, and info log
- Observe slow drifts in performance—often the first hint of underlying failure
Step 2: Enable Fast Feedback Loops
Automation without rapid feedback invites hidden risks. Integrate notifications into Slack, Teams, or email to alert you as soon as anything deviates from the norm. Configure dashboards for “red flags,” not just failures.

Step 3: Use Automated Smoke Tests and Health Checks
Before major runs, have automated scripts run “smoke tests” to validate system health and prerequisite conditions. This catches obvious misconfigurations before a bigger failure.
Step 4: Implement Meaningful Logging & Intelligent Alerting
Good logging tells you not only what failed but provides context (stack traces, environment details, timestamps). Smart alerts should trigger only for events that require human review—not for every minor warning.

Step 5: Apply Integration and Regression Testing—at Every Stage
Automated systems don’t operate in silos. Build tests that cover not just component behavior, but integration points and rapidly changing environment configurations. Use regression tests to identify unexpected breakages, especially after updates.
Step 6: Prioritize Fail-Fast Patterns
Fail-fast means that as soon as a problem is detected, the process halts and alerts the team. It’s better to stop and fix immediately than let automation limp along, generating data or assets that have to be cleaned up later.
Step 7: Utilize Predictive and Self-Healing Mechanisms
Modern automation can leverage AI/ML models to spot anomalies before a human ever would. Some platforms self-heal: if a known transient error is spotted, the system retries or rolls back automatically to recover without interruption.
Step 8: Document Patterns, Share Learnings, and Bake in Retrospectives
Regularly review all failure incidents—even the near-misses! Document root causes, update your playbooks, and improve your monitoring configuration. Foster a culture where reporting failures is rewarded, not penalized.
Major Challenges, Myths, & Objections in Early Failure Detection
Despite clear benefits, organizations face real barriers when trying to detect automation failure early:
- Myth: “Automation is set-and-forget.” Reality: All automation requires continuous oversight and evolution.
- High Noise, Low Signal: Too many alerts desensitize teams to genuine issues. Calibrate for meaningful feedback, not noise.
- Lack of Observability: Legacy systems often lack built-in metrics and logging, making early detection harder.
- Skill Gaps: Teams may lack expertise in proper logging, alerting, or using analytics tools effectively.
- Fragmented Tools: When monitoring, CI, and automation live in separate silos, failures frequently fall through the cracks.
- Cultural Resistance: Teams may worry about blame or “bad KPIs” surfacing from increased transparency—shift to a blameless, learning-first mindset.
Knowing these pitfalls unlocks the potential for teams to build not only better automation, but more resilient, adaptive organizations that spot and learn from every incident.
FAQs About How to Detect Automation Failure Early
1. What are some common signs of automation failure?
Unexpected increases in execution time, test flakiness, recurring environment errors, and inconsistent test results are just a few. Often, subtle patterns like increased resource consumption or degraded data quality signal emerging problems.
2. Why do so many automation projects fail without being noticed initially?
Many failures are silent at first—misconfigured scripts, expired credentials, or environment shifts might not cause outright errors, but slowly erode effectiveness until a critical point is reached.
3. How can I minimize false positives in my automation monitoring?
Fine-tune your alerts to trigger only for actionable thresholds, not every warning. Combine multiple data points (such as log errors + performance drift) to increase signal quality.
4. What tools help with early detection of automation failure?
Options like Datadog, New Relic, Sumo Logic, and TestSigma provide monitoring, alerting, and even AI-driven anomaly detection. Integrate with Slack/Teams for real-time team visibility.
5. How often should I review automation errors and failures?
The best teams review failures after every run (using dashboards) and at regular retrospectives. Frequent review uncovers patterns and enables continuous improvement.
6. What’s the difference between fail-fast and fail-safe in automation?
Fail-fast stops a process as soon as a problem is detected—enabling immediate feedback and corrective action. Fail-safe attempts to recover or continue, which risks hiding deeper issues.
7. Can machine learning help detect automation failure early?
Yes—AI/ML can analyze massive historical and live data streams to spot outliers or abnormal patterns that humans might miss, surfacing hidden errors before they escalate.
8. How should I handle “flaky” automation tests?
Track test flakiness over time. Investigate root causes (timing, data, environment). Flag or quarantine chronically flaky tests to prevent them from masking real regressions.
9. What key metrics should I monitor for early automation failure detection?
Monitor runtime, failure rates, error patterns, resource utilization, and any drift in baseline. Set up trend alerts for small but persistent changes—even before outright failures.
10. How do I create a culture where early failure detection is valued?
Reward teams for surfacing issues early. Use blameless postmortems. Celebrate insights that prevent bigger outages, not just “hero fixes” after failure strikes.
11. Is it possible to automate the detection process itself?
Absolutely—set up automation to watch for known error patterns, unexpected output, or resource spikes. Let automation notify you of automation failures!
12. How do integration failures differ from unit test failures in automation?
Unit test issues are isolated, while integration failures can break entire pipelines and chain systems. Prioritize integration monitoring to spot hidden cross-cutting risks.
13. What should be included in every automation failure alert?
Include error logs, environment information, affected components, time of failure, and actionable next steps/who to contact for resolution.
Conclusion: Turn Early Failure Detection Into Your Automation Superpower
In every organization, automation is meant to accelerate innovation—not multiply silent risks. Learning how to detect automation failure early is about vigilance, proactive tooling, and cultural buy-in. By tracking the right metrics, enabling rapid feedback, and fostering an environment where failures become learning opportunities, you transform reliability from “nice-to-have” to non-negotiable. Embrace fail-fast, monitor wisely, and let your automation deliver on its true promise: resilience at scale.
For more detailed implementation tips and automation insights, visit our resources page or reach out to the DigitalWithSandip team—and start securing your pipelines before failure strikes.